
本文介绍了AI绘画入门的一些基础知识和操作方法,包括在Mac M1上部署Stable Diffusion WebUI、汉化、制作精美图片和解释一些常见名词和问题。
《送元二使安西》
渭城朝雨浥轻尘,客舍青青柳色新。
劝君更尽一杯酒,西出阳关无故人。
-唐代王维
前言
当今社会,人工智能技术的应用越来越广泛,其中一项非常有趣的应用就是AI绘画。通过使用AI绘画技术,我们可以创作出各种各样的精美图片,这些图片可以用于艺术创作、设计、广告等领域,甚至可以成为一种新的商业模式。本文将介绍AI绘画的基础知识和操作方法,包括如何在Mac M1上部署Stable Diffusion WebUI、如何进行汉化、如何制作出和C站上一样精美的图片,以及一些常见问题和名词解释。希望本文可以为对AI绘画感兴趣的读者提供一些参考和帮助。
Stable Diffusion
Stable Diffusion是2022年发布的深度学习文本到图像生成模型。它主要用于根据文本的描述产生详细图像,尽管它也可以应用于其他任务,如内补绘制、外补绘制,以及在提示词(英语)指导下产生图生图的翻译。
它是一种潜在扩散模型,Stable Diffusion的代码和模型权重已公开发布,可以在大多数配备有适度GPU的电脑硬件上运行。我们可以使用开源项目https://github.com/AUTOMATIC1111/stable-diffusion-webui图形化管理界面生成图片。
在Mac M1上部署Stable Diffusion WebUI
安装国内源的homebrew1
/bin/bash -c "$(curl -fsSL https://gitee.com/ineo6/homebrew-install/raw/master/install.sh)"
使用homebrew安装依赖项:1
brew install cmake protobuf rust python@3.10 git wget
克隆stable-diffusion-webui项目:1
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
下载模型
初学者可以通过C站https://civitai.com/ (注意上面有很多18+内容NSFW)下载模型,可以找一个自己喜欢的类型图下载对应的模型,比如我找到的一个专门用于绘制龙的Lora模型,基于Stable Diffusion 1.5版本训练生成的。点击下载保存到stable-diffusion-webui/models/Lora/文件夹中。
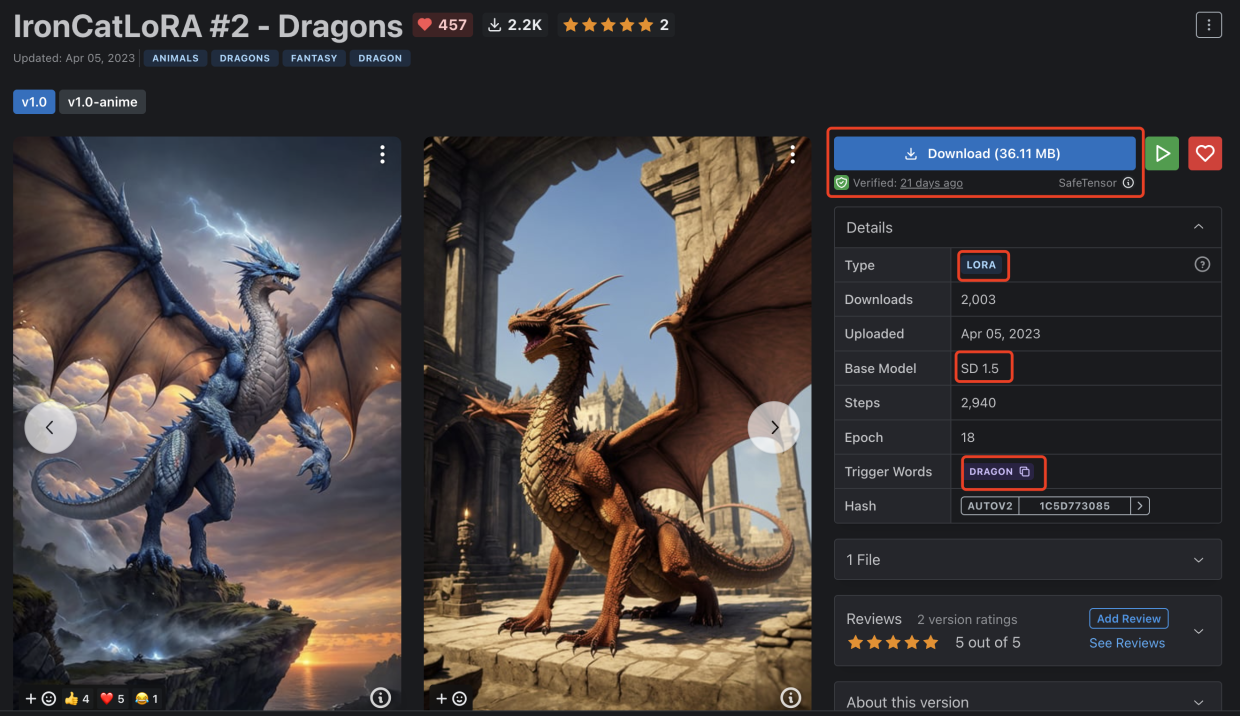
IronCatLoRA #2 - Dragons模型详情地址:https://civitai.com/models/30151/ironcatlora-2-dragons?modelVersionId=36321
点击第一张示例图,从页面右侧可以看到这张图片使用了两个模型,上面的是名为IronCatLoRA #2 - Dragons的LORA微调模型,下面的是名为Deliberate的CheckPoint大模型,点击可以进入到模型详情页进行下载,还可以点击页面下面的按钮复制生成的所有数据。
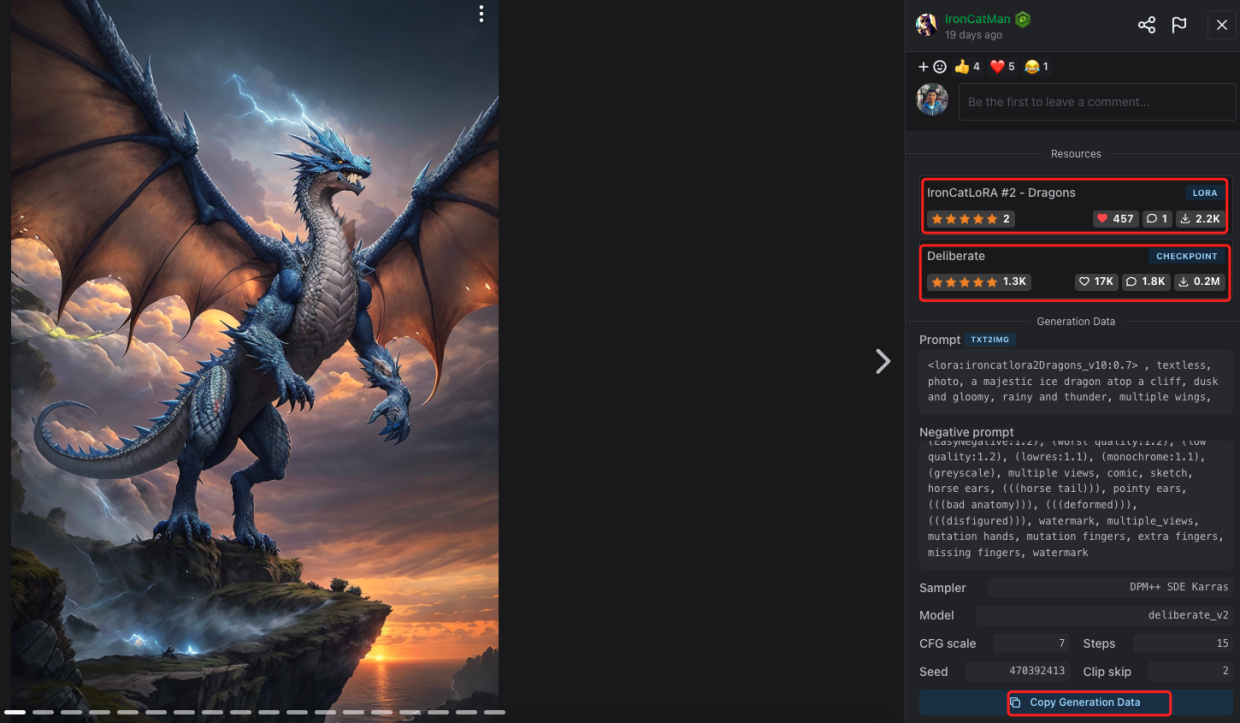
点击上面图片的第二个模型Deliberate大模型进入到详情页,可以看到这个模型的类型是checkpoint merge,基础模型是Stable Diffusion 1.5版本,也就是说这个模型是基于Stable Diffusion 1.5版本合并其他模型产生的大模型。点击下载按钮开始下载大模型,保存到 stable-diffusion-webui/models/Stable-diffusion/文件夹中。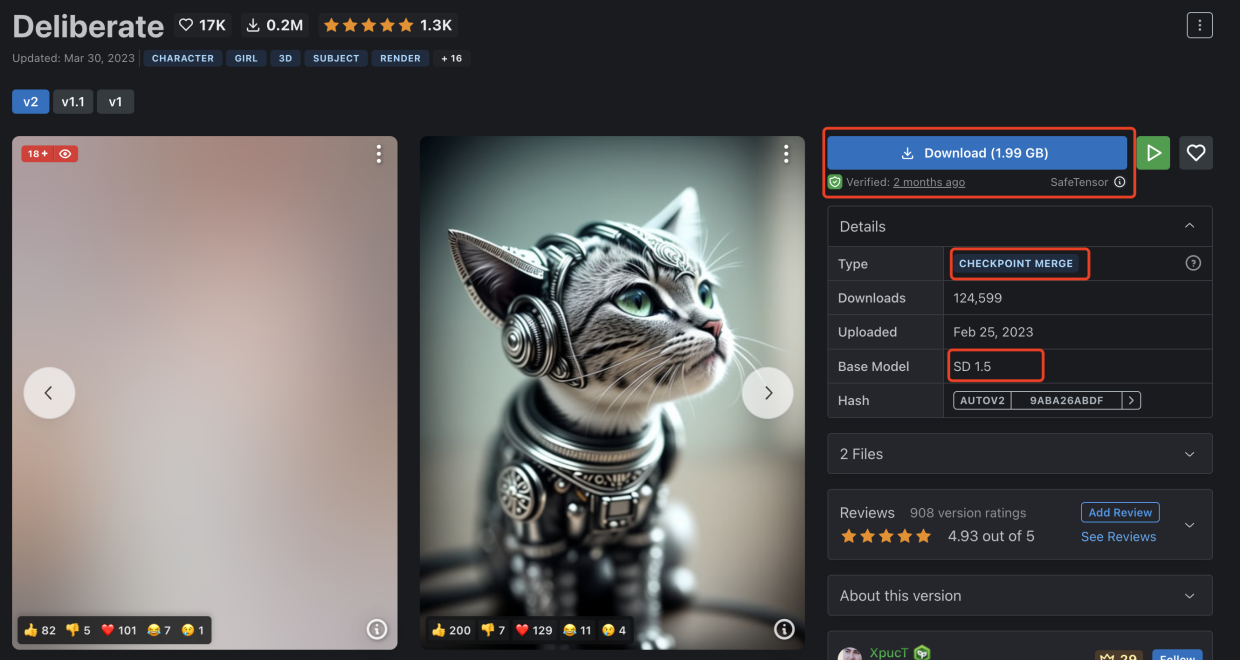
Deliberate大模型详情页地址:https://civitai.com/models/4823/deliberate?modelVersionId=15236
运行
在运行之前可以提前安装下gfpgan,不然首次运行会容易卡住:1
pip3 install gfpgan
cd到stable-diffusion-webui目录,运行webui.sh1
./webui.sh
然后用浏览器打开:1
http://127.0.0.1:7860/
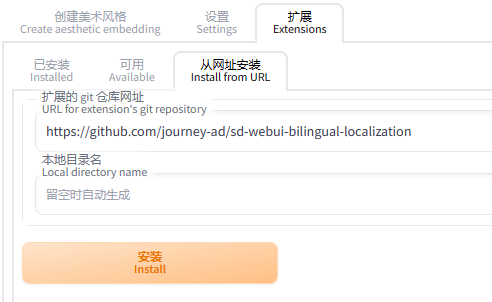
安装双语插件
点击Extensions–>install from URL,输入插件地址https://github.com/journey-ad/sd-webui-bilingual-localization,点击install:
安装中文语言包
输入插件地址https://github.com/dtlnor/stable-diffusion-webui-localization-zh_CN,点击install即可。
启用插件
安装完插件后,默认是禁用所有插件的,需要修改为none开启所有插件
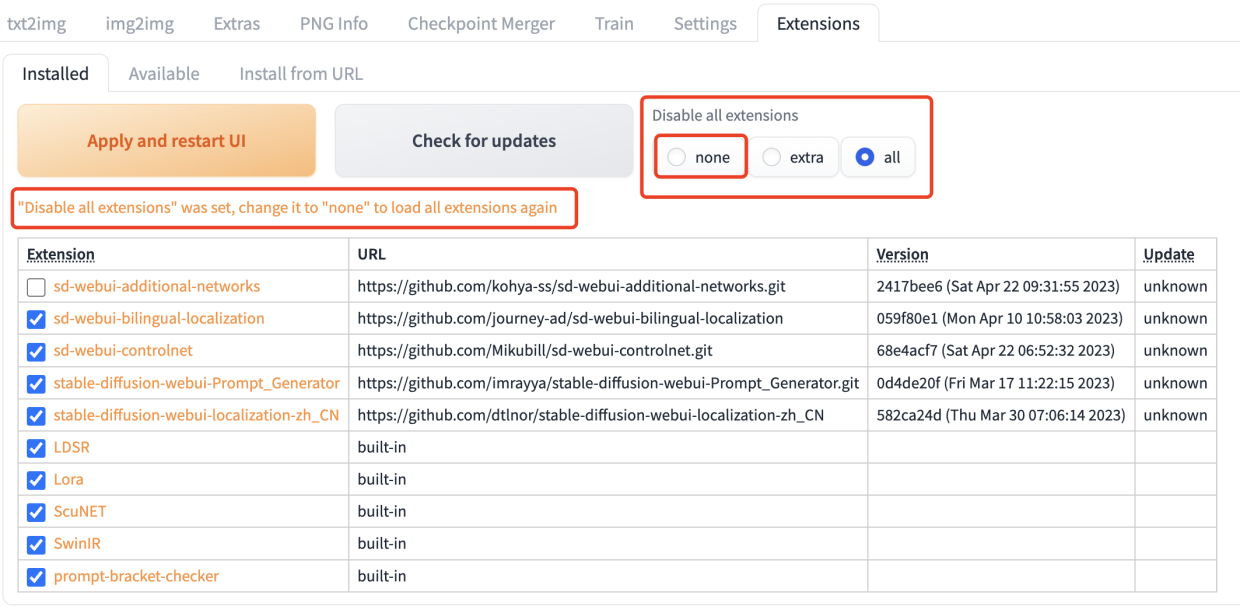
注意需要保证 Settings - User interface - Localization 设置为 None
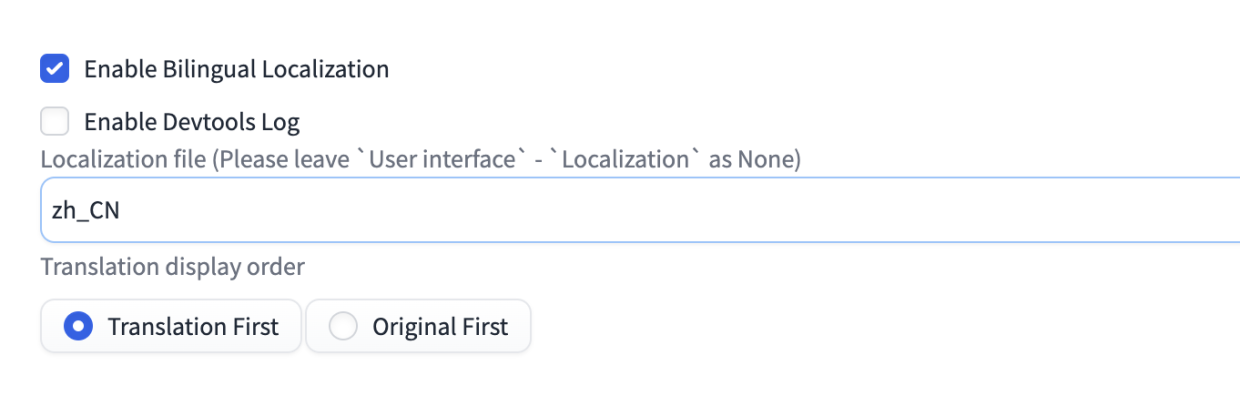
在Settings - Bilingual Localization 面板中,选择中文语言包zh_CN,然后点击Apply settings 和Read UI按钮即可生效。
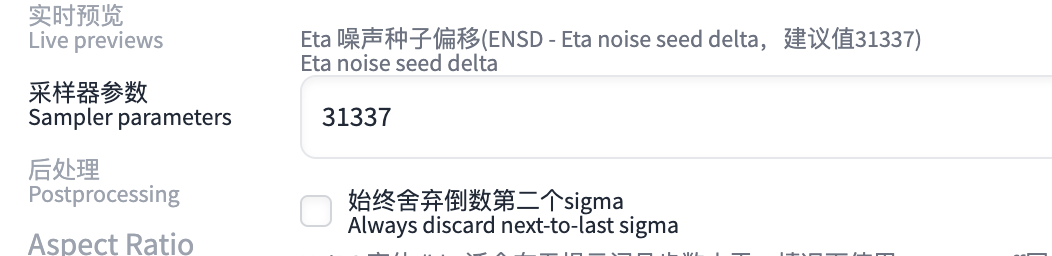
通用配置
设置-采样器参数-ENSD-设置为31337
生成图片
从上面的图片详情页点击复制生成数据按钮,然后粘贴到提示词输入框中,点击生成下面的斜箭头按钮,从提示词中读取生成参数。
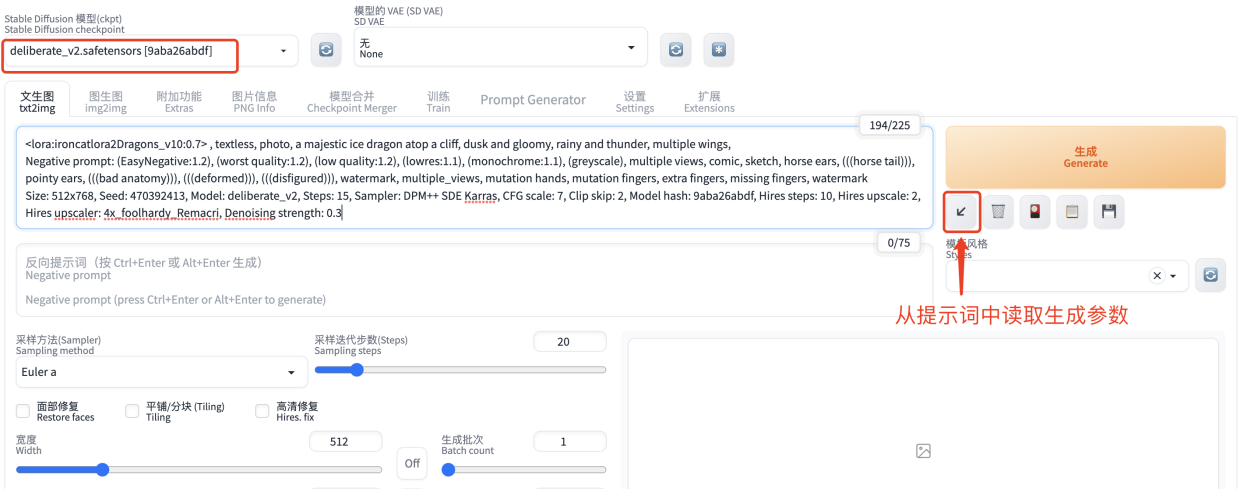
示例图中开启了高清修复,由于电脑性能原因我们这里取消勾选高清修复选项,然后点击生成按钮。
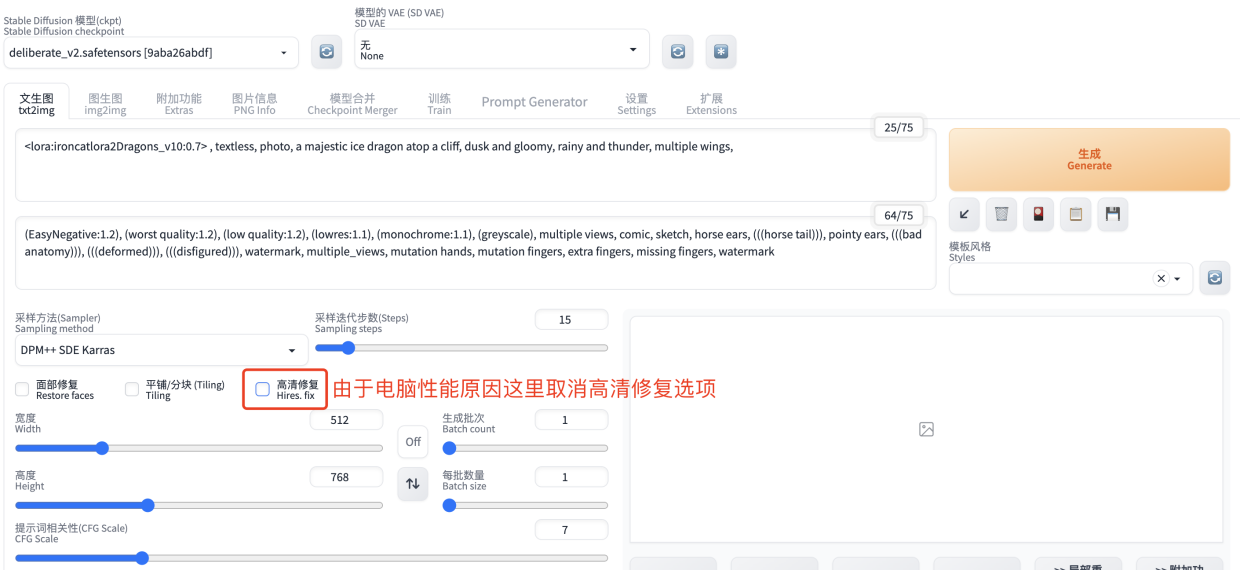
大概两三分钟后会生成一张图片,样子跟示例图效果差不多,如果打开高清修复图片尺寸会更大一些也会更清晰一些。
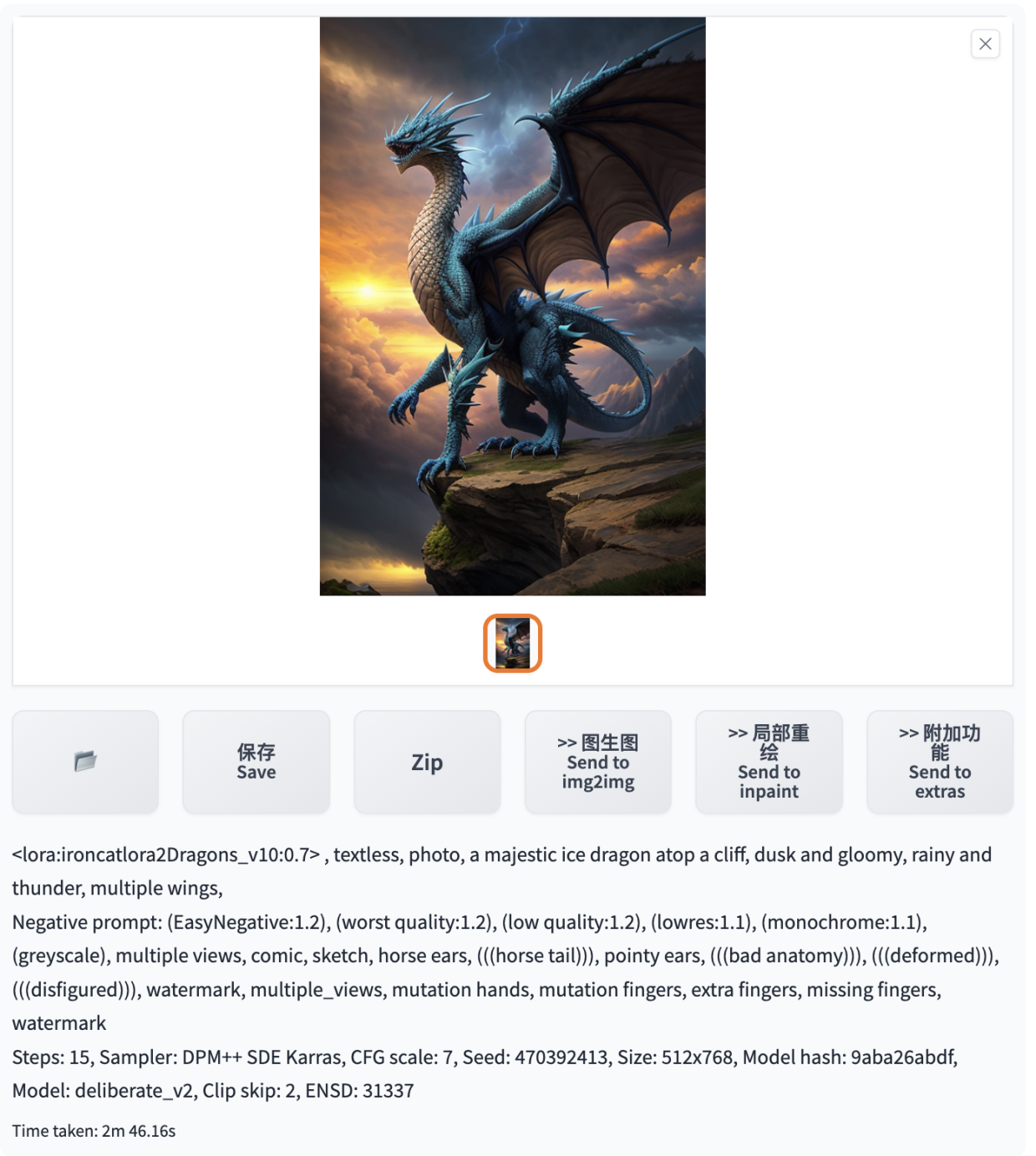

最后再来欣赏下高清示例图:

名词解释
1.什么是大模型?
在C站上标签为CHECKPOINT的都是大模型,基本都是在Stable Diffusion大模型基础上合并而来,Stable Diffusion大模型可以理解为更通用,这是生成图片的基础模型,大小一般在几个G。
2.什么是LORA模型?
LORA模型是大模型的基础上进行的微调,经过固定风格图片训练产生的模型,大小一般在几十兆到几百兆。
3.什么是VAE模型?
大部分大模型内都包含了VAE模型,也有的大模型不包含VAE模型,VAE模型可以提高图片生成的质量,用于细节修复,特别是眼睛和文字,如果需要搭配VAE的大模型,在模型详情页一般都会有说明,比如Realistic Vision大模型推荐搭配VAE模型使用:
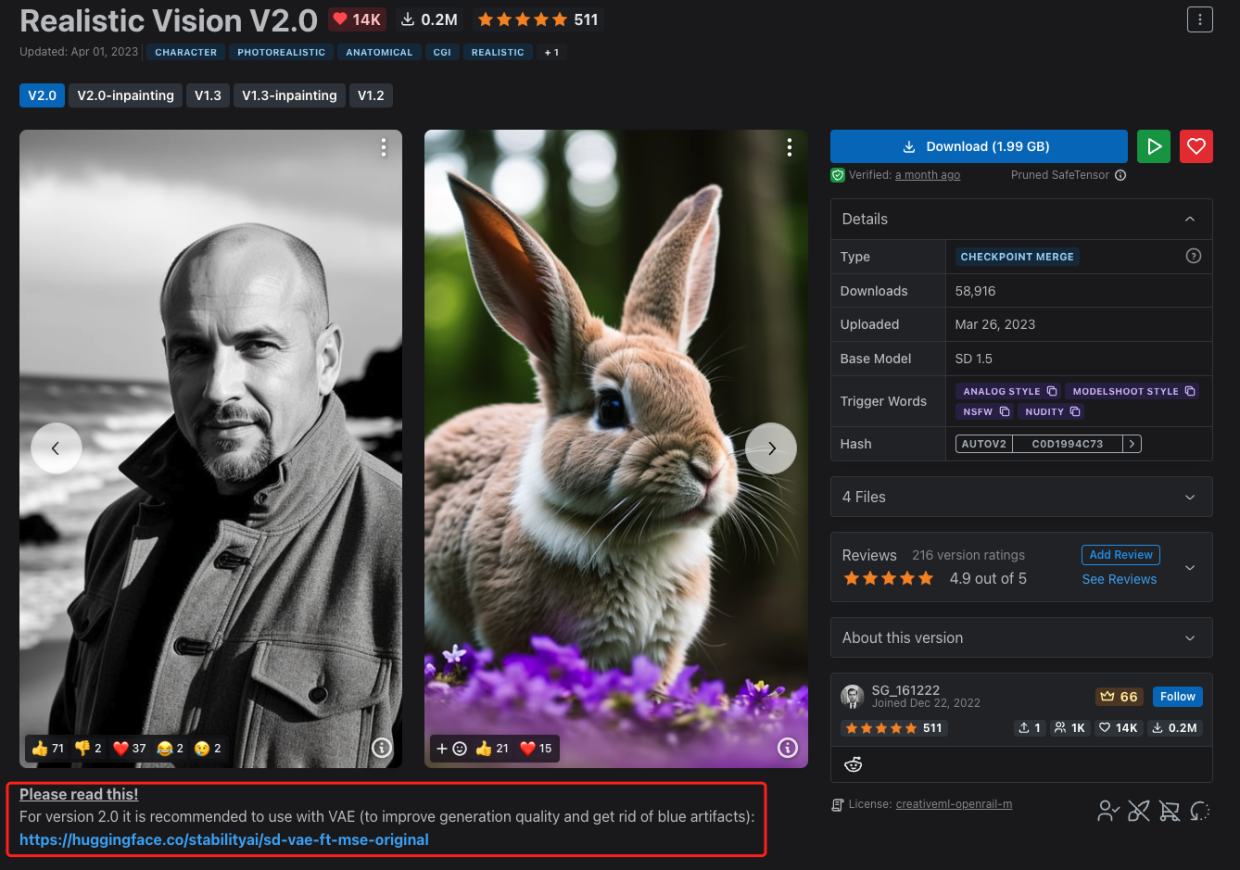
Realistic Vision V2.0模型详情地址:https://civitai.com/models/4201/realistic-vision-v20
4.如何使用VAE模型?
将对应的VAE模型下载后保存到stable-diffusion-webui/models/VAE/文件夹中,然后在生成图片之前选择相应的VAE模型即可。

5.模型文件名后缀ckpt和safetensors有什么区别?
顾名思义,safetensors模型相对ckpt更为安全,如果有safetensors格式的模型,推荐下载safetensors格式的模型。
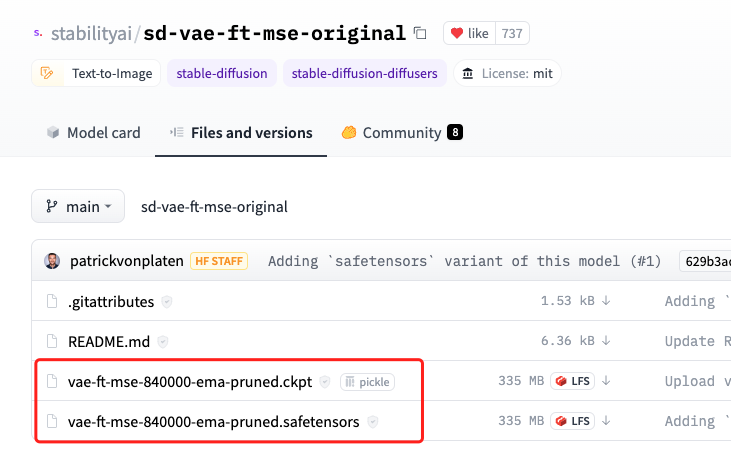
6.模型文件名中的单词都是什么含义?
full:全模型,如果训练的话需要使用全模型。
pruned:精简模型,把生成不好的内容都去掉了,适合文生图,相对全模型文件更小,推荐使用。
ema:压缩模型,生成的图片质量不高,不推荐使用,也可以使用模型转换插件转换为nonema模型。
常见问题
1.生成的图片色彩发灰?
看一下使用的模型详情页有没有对应的VAE模型,如果有需要挂载上,否则可能会出现图片发灰的情况。
2.在图片生成进度70%左右的时候看着还行,但最后生成的图片很糊,简直没法看,就像下图一样:

可以通过在启动的时候添加以下参数解决上面的问题:1
./webui.sh --opt-split-attention-v1
重新生成的图片:

3.有一些模型点击生成后会直接报错,在生成图片的时候可能会遇到这个问题1
2
3
4
5/AppleInternal/Library/BuildRoots/c651a45f-806e-11ed-a221-7ef33c48bc85/Library/Caches/com.apple.xbs/Sources/MetalPerformanceShaders/MPSCore/Types/MPSNDArray.mm:794: failed assertion `[MPSNDArray, initWithBuffer:descriptor:] Error: buffer is not large enough. Must be 4915200 bytes
'
[1] 6826 abort ./webui.sh --opt-split-attention-v1
/opt/homebrew/Cellar/python@3.10/3.10.11/Frameworks/Python.framework/Versions/3.10/lib/python3.10/multiprocessing/resource_tracker.py:224: UserWarning: resource_tracker: There appear to be 1 leaked semaphore objects to clean up at shutdown
warnings.warn('resource_tracker: There appear to be %d '
解决办法:用文本编辑器打开webui-user.sh文件,修改#export COMMANDLINE_ARGS=""为export COMMANDLINE_ARGS="--skip-torch-cuda-test --no-half --use-cpu all,然后保存,重新启动./webui.sh。
在配置很低的电脑上运行
目前macOS上的GPU加速会使用大量内存,如果性能很差(如果用任何采样器用20步生成512x512的图像需要超过一分钟),可以在启动时尝试添加--opt-split-attention-v1参数:1
./webui.sh --opt-split-attention-v1
如果跟之前没什么区别,打开活动监视器看下内存占用是不是快满了,如果内存压力图显示为红色,可以尝试再添加一个--medvram参数:1
./webui.sh --opt-split-attention-v1 --medvram
如果内存占用还是很多,可以改为--lowvram参数:1
./webui.sh --opt-split-attention-v1 --lowvram
如果使用任何采样器用20步生成一个512x512的图像,仍然需要几分钟以上的时间,那么您可能需要关闭GPU加速,用文本文件打开webui-user.sh文件,把#export COMMANDLINE_ARGS=""这一行内容修改为下面的内容:1
export COMMANDLINE_ARGS="--skip-torch-cuda-test --no-half --use-cpu all"
以上内容翻译自这个文档,如果在使用过程中遇到其他问题,也可以从这里寻找答案:https://github.com/AUTOMATIC1111/stable-diffusion-webui/discussions/5461
总结
本文介绍了AI绘画入门的一些基础知识和操作方法,包括在Mac M1上部署Stable Diffusion WebUI、汉化、制作精美图片和解释一些常见名词和问题。希望可以帮助你快速入门AI绘画。
