
本文介绍了Android中的R文件的作用以及规则,分析了滴滴booster和字节跳动ByteX提供的R资源inline的原理,最后提供了一个gradle插件扫描class中可能使用反射获取资源id的类信息并输出可能的id集合,用于帮助配置白名单。
《芙蓉楼送辛渐》
寒雨连江夜入吴,平明送客楚山孤。
洛阳亲友如相问,一片冰心在玉壶。
-王昌龄
前言
Android在构建过程中会根据资源生成R文件,里面包含了资源索引,使用该索引可以在最终生成的resources.arsc资源映射表中找到对应资源,对于开发者来说在代码中引用资源很方便。
在Library工程中引用的R资源索引不是final的,所以我们在Library工程不能在switch - case 和Annotation中使用资源索引。由于引用的资源不是final的,所以Library的产物aar中包含的class中使用的资源索引还是会以包名存在。
在App工程中构建时会将依赖的AAR资源进行合并,根据合并的结果生成最终的R资源索引,这时的资源索引已经确定,所以全部是final的,java编译器在编译时会将final常量进行inline内联操作,也就是App工程中的java源码编译后的class中使用的R资源索引全部会替换为常量值。
如果Library A依赖了Library B,则Library A包名的R资源文件中包含所有Library B的资源索引,所以在代码中既可以引用Library A包名的R资源索引使用Library B中的资源,也可以使用Library B包名的R资源索引使用Library B中的资源。
App工程依赖了所有的Library,所以资源合并后R资源包含所有Library的资源索引。
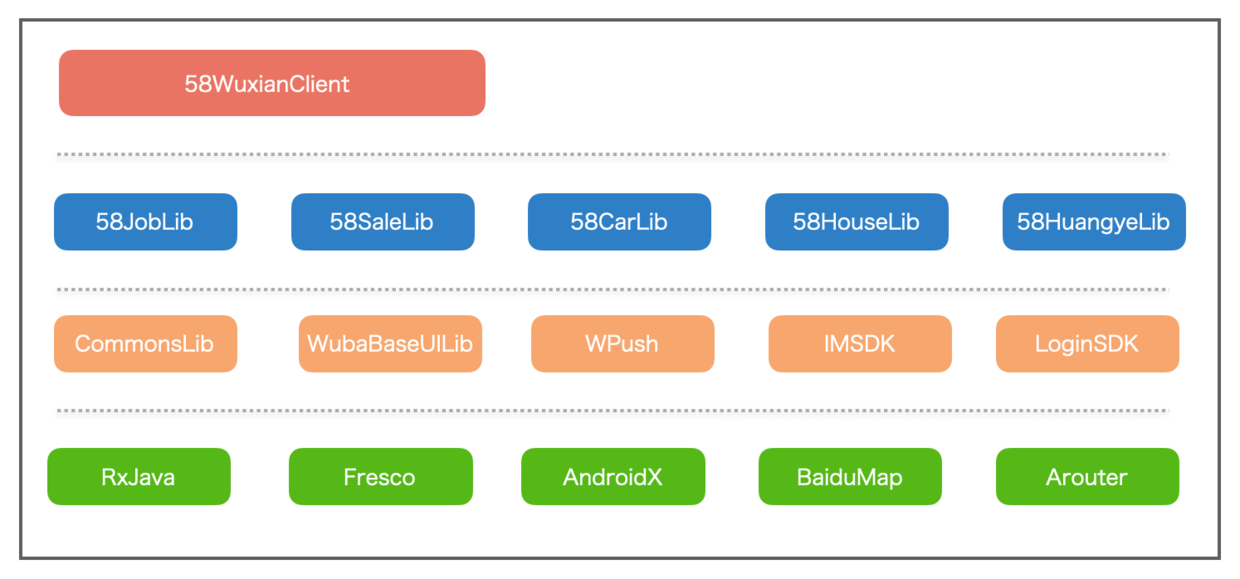
这个是58同城工程简版架构图,最上层是壳工程,依赖所有业务库,第二层是业务库会根据业务需要依赖三方库,每个业务库都依赖了很多三方库,所以根据上面提到的资源合并规则,可以预见R文件占用了很大的包大小空间。
目前市面上有很多使用AOP技术将R资源内联到class文件中的方案,这里我们分析下滴滴出品的booster和字节跳动维护的ByteX。
滴滴booster的R资源inline原理
滴滴booster中提供了很多实用的插件,这里我们只分析对R资源inline的插件。滴滴R资源inline的用法很简单,添加依赖的插件即可,然后可以在gradle.properties文件中配置要忽略处理的包名:1
booster.transform.r.inline.ignores=android/*,androidx/*
首先从 Symbol List(R.txt)文件中解析所有资源信息,如果依赖中包含constraintlayout,然后从布局文件中解析所有constraint用到的相关id,比如constraint_referenced_ids和layout_constraint属性引用的id,如果有contraint相关的id,则默认keep所有constraint相关R,也就是在ignores的集合中加上android/support/constraint/R$id和androidx/constraintlayout/R$id。
然后进入到真正的处理过程:
1.如果classname全类名匹配指定的忽略包名,则忽略。
2.如果是R文件并且不是应用包名的styleable资源,则默认清除所有field。
3.最后就到了最关键的步骤,根据引用的R资源的类型和名称从symbol集合中获取资源的常量值完成替换,这里会忽略引用android内部的R资源com/android/internal/R$和android/R$,如果是int数组则修改引用的library包名为应用包名。
为什么没有对styleable资源进行处理?文档中给出的说明是:在 R 的字段,styleable 字段是一个例外,它不是常量,它是 int[]。
最后可以在build文件夹中找到报告文件,里面包含被inline的集合和被清除field的文件集合。
总结:使用方便,逻辑清晰,library的R资源的Fields会全部删除,并将引用Library包名的int数组会全部修改为应用包名,应用包名的R的styleable资源会全部保留。需要注意的是Library的R class没有被删除,所以应用中即使使用了反射获取资源id时也不会造成应用崩溃,使用反射肯定捕获了异常,但可能会造成页面异常,另外不支持根据资源名配置白名单,只能根据包名进行配置。
字节跳动ByteX的R资源inline原理
ByteX和滴滴booster类似,提供了很多实用插件,这里我们只分析下对R资源inline插件的处理。
这里定义了4个集合,分别用于存放应该被删除的R文件、应该被inline的R资源、应该跳过inline的R资源和白名单。1
2
3
4private final Set<String> shouldDiscardRClasses = ConcurrentHashMap.newKeySet(1000);
private final Map<String, Map<String, Object>> shouldBeInlinedRFields = new ConcurrentHashMap<>(3000);
private final Map<String, Map<String, Object>> shouldSkipInlineRFields = new ConcurrentHashMap<>(3000);
private final Map<String, Set<Pair<Pattern, Pattern>>> mWhiteList = new HashMap<>();
在transform之前会遍历R文件的class,收集R资源相关信息,流程如下:
1.首先默认当前R文件class是可以被删除的。
2.如果是静态final int的field并且没有在白名单中则添加到shouldBeInlinedRFields集合中,否则添加到shouldSkipInlineRFields集合中,标记当前class不能被删除。
3.如果当前R文件所有field没有在白名单中则添加到shouldDiscardRClasses集合中,也就是该R文件class是可以被删除的。
4.如果扫描到Styleable class的<clinit>方法时,<clinit>方法用于初始化静态变量和静态代码块,并且不需要保留该类时,会使用AnalyzeStyleableClassVisitor处理,如果数组大小和计算的大小一致则加到shouldBeInlinedRFields集合,否则抛出异常。
在开始transform之前,处理了一些和R资源inline无关的事情:
1.如果开启了compatRFileAssignInherit,也就是对R文件使用继承方式进行分割,然后计算需要被删除的R集合,也就是将所有R子类从应该被删除(discardable)的集合中移除,默认不开启。
2.res和assets无用资源的检查准备,默认不开启。
开始transform的流程:
1.如果在shouldDiscardRClasses集合中,transform方法返回false,最终该class会被删除。
2.然后使用ClassVisitor对class文件进行扫描,如果是R文件class扫描到Field并且在shouldBeInlined集合中,则删除。
3.如果不是R文件class扫描到方法,使用MethodVisitor对方法进行扫描。
4.扫描到方法中的Field时,从shouldBeInlined集合中获取对应的值进行inline处理,这里包括Styleable class的int数组。如果shouldBeInlined集合中没有找到,则记录到NotFoundRField集合中,最后输出到日志中。这可以帮我们找到aar中错误引用的R资源,例如Library A中的布局文件中包含test的id被App工程同名布局文件不包含test的id覆盖了,但Library A的class中还是引用了test的id,这可能会造成应用崩溃,如果有这种情况,我们可以在最后的报告文件中找到。
5.扫描到方法中的visitLdcInsn时,判断字符串或引用类型的类名是不是匹配R类名,如果匹配则输出日志进行提醒可能用到了反射获取。
在transform之后的流程:
1.将NotFoundRField输出日志到文件,如果开启StrictCheckMode则抛出异常。
2.然后是无用资源报告。
最后可以在build文件夹找到报告文件,里面还包含方便查看的网页文件。
网页的报告里面包含插件的执行时间、可能使用反射获取R资源的类信息、保留的资源信息和被删除的资源文件信息。
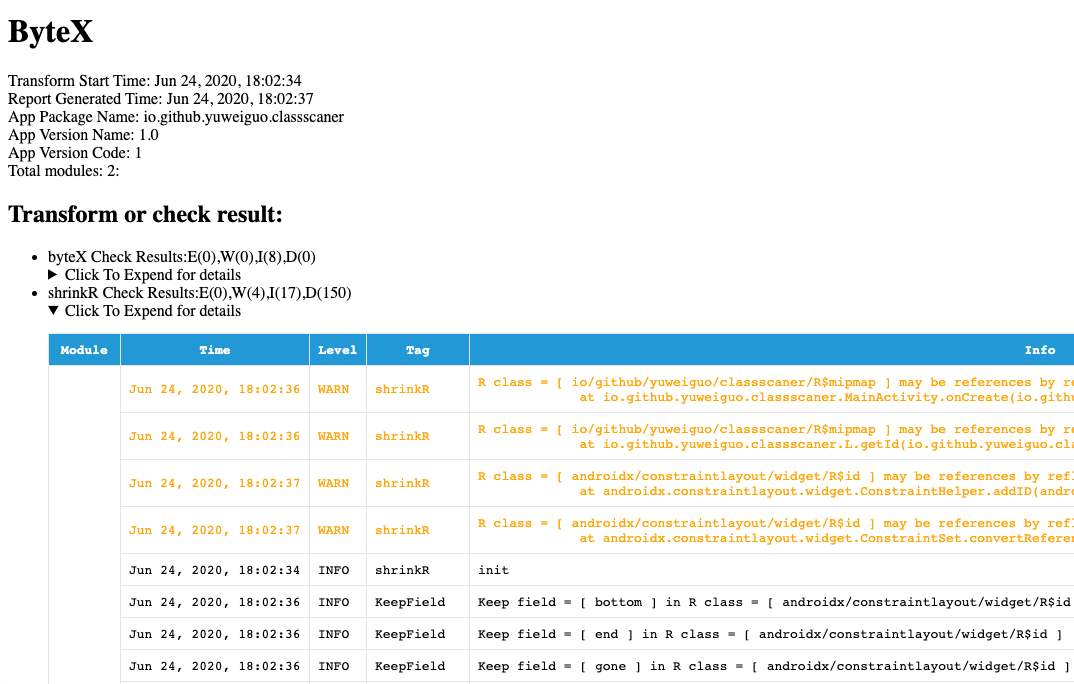
从这个报告方便我们找出可能使用反射获取资源的类信息,然后将相关资源添加到白名单,避免由于R资源inline引用应用崩溃。
扫描Class获取可能使用反射获取的id
使用反射获取资源id时通常会使用类似下面的代码封装为一个方法或者直接写在需要的地方:1
2
3
4
5
6
7
8
9
10public static int getId(String num){
try {
String name = "weather_detail_icon_" + num;
Field field = R.drawable.class.getField(name);
return field.getInt(null);
} catch (Exception e) {
e.printStackTrace();
}
return 0;
}
这里需要注意的是不需要考虑使用getResources().getIdentifier这种方式获取id的代码,因为这种方式并没有用到R资源索引文件,而是直接使用native从resources.arsc资源映射表获取的资源id。
这里提供了一个插件用于扫描class获取可能使用反射获取的资源id集合,传送门:https://github.com/yuweiguocn/Scanner
1 | //添加工程最外层gradle文件中下面的依赖: |
扫描结果可以在build/outputs目录下的scanner_result.json文件中找到:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15{
"possibleRids": [
"io.github.yuweiguo.classscaner.R.mipmap.ic_launcher",
"io.github.yuweiguo.classscaner.R.mipmap.testcall",
"io.github.yuweiguo.classscaner.R.mipmap.testcall2",
"io.github.yuweiguo.classscaner.R.mipmap.weather_detail_icon_"
],
"getResource": [
"directCall io.github.yuweiguo.classscaner.L.getId(): 18 { java.lang.reflect.Field.getInt }",
"directCall io.github.yuweiguo.classscaner.MainActivity.onCreate(): 18 { java.lang.reflect.Field.getInt }",
"indirectCall io.github.yuweiguo.classscaner.MainActivity.test(): 34 { io.github.yuweiguo.classscaner.L.getId }",
"indirectCall io.github.yuweiguo.classscaner.MainActivity.test2(): 30 { io.github.yuweiguo.classscaner.L.getId }"
],
...
}
插件会进行两次扫描,第一次扫描收集所有使用反射的集合,包含class名称和method名称;第二次扫描收集所有反射和间接调用包含反射方法的集合,间接调用就是调用了第一次集合中的方法。这个插件只是提供了一个简单的结果,最终还是需要人工确认相关信息。
总结
滴滴booster通过解析R.txt文件效率上要高于扫描class,使用方便,逻辑清晰,library的R资源的Fields会全部删除,并将引用Library包名的int数组会全部修改为应用包名,应用包名的R的styleable资源会全部保留。需要注意的是Library的R class没有被删除,所以应用中即使使用了反射获取资源id时也不会造成应用崩溃,使用反射肯定捕获了异常,但可能会造成页面异常,另外不支持根据资源名配置白名单,只能根据包名进行配置。
字节跳动的ByteX会扫描所有R文件class并将相关信息存储到集合中,支持根据包名和资源名配置白名单,对Styleable class的int数组也做了inline处理,并且将无用R文件class进行了删除,最后还提供了html的报告,里面包含可能使用反射获取R资源的类信息,这可以帮助我们更好地配置白名单,由于R文件class也会被删除,所以如果应用使用反射获取资源可能会直接崩溃。
相对于滴滴booster,字节跳动的ByteX将无用R文件class也进行了删除和R资源中的int数组也进行了inline内联处理,处理更彻底。所以我们最终选择了ByteX,使用最后提供的插件配置白名单,58app在使用ByteX将R资源inline后,包大小减少了4.6M,dex数量从16个减到了11个。
参考
- https://github.com/didi/booster
- https://booster.johnsonlee.io/feature/shrink/res-index-inline.html
- https://github.com/bytedance/ByteX
