
本文对 java 中 volatile 关键字的作用及使用进行了详细介绍。
《春晓》
春眠不觉晓,处处闻啼鸟。
夜来风雨声,花落知多少?
—唐,孟浩然
作用
volatile作用主要有两个,一是保证多线程环境下共享变量的可见性,二是禁止指令重排序。
缓存一致性
首先从计算机的内存模型和Java内存模型来分析下多线程环境下普通共享变量的可见性问题。
计算机内存模型
通常称被多个线程访问的变量称为 共享变量。可见性是指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。
我们运行的程序会被编译成指令放到CPU中运行,程序在运行过程中的临时数据放在主存(物理内存)中,由于CPU的运算速度很快,但从主存数据读取和写入速度很慢,所以为了提高CPU运算效率,在CPU中开辟了一块存储称之为高速缓存。程序在运行过程中,会将需要的数据复制一份到高速缓存,这样CPU在执行指令时会从高速缓存中读取和写入数据,运算过程结束会将数据从高速缓存中写回到主存。
高速缓存在单线程中是没问题的,但在多线程中可能会出现问题。在多核CPU 中,每条线程可能运行于不同的 CPU 中,因此 每个线程运行时有自己的高速缓存(对单核CPU来说,其实也会出现这种问题,只不过是以线程调度的形式来分别执行的)。举个例子,下面的代码由两个线程运行,i 的初始值为0:1
i = i + 1;
两个线程分别读取 i 的值到各自所在CPU的高速缓存中,线程1执行加1操作后 i 的值为1,然后将 i 的值写入到主存中,然后线程2执行加1操作,由于线程2的高速缓存中 i 的值为0,所以执行加1操作后 i 的值为1,线程2将 i 的值写入到主存中,最终 i 的值是1而不是2,这就是著名的缓存一致性问题 。为了解决缓存不一致的问题,在硬件层面通常有两种解决方案:一是缓存一致性协议,二是通过在总线加Lock#锁的方式。这里我们不再深入介绍。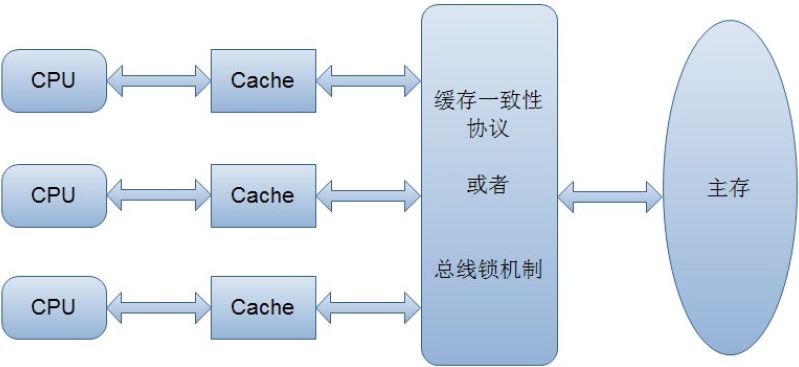
Java内存模型
Java内存模型规定所有的变量都是存在主存当中(类似于前面说的物理内存),每个线程都有自己的工作内存(类似于前面的高速缓存)。线程对变量的所有操作都必须在工作内存中进行,而不能直接对主存进行操作。并且每个线程不能访问其他线程的工作内存。所以在Java内存模型中同样存在一致性问题。
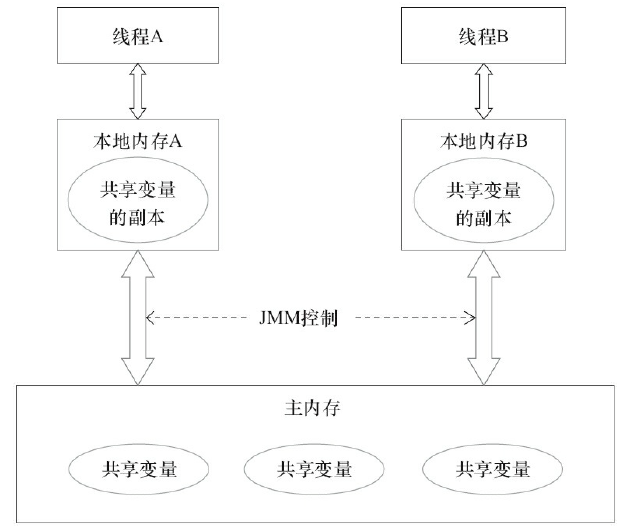
使用 volatile 保证可见性
对于可见性,Java提供了 volatile 关键字来保证可见性。当一个共享变量被 volatile 修饰时,它会保证修改的值会立即被更新到主存,当有其他线程需要读取时,它会去内存中读取新值。而普通的共享变量不能保证可见性,因为普通共享变量被修改之后,什么时候被写入主存是不确定的,当其他线程去读取时,此时内存中可能还是原来的旧值,因此无法保证可见性。
来看一段代码,假如线程1先执行,线程2后执行:1
2
3
4
5
6
7//线程1
boolean stop = false;
while(!stop){
doSomething();
}
//线程2
stop = true;
这段代码是很典型的一段代码,很多人在中断线程时可能都会采用这种标记办法。但是事实上,这段代码会完全运行正确么?即一定会将线程中断么?不一定,也许在大多数时候,这个代码能够把线程中断,但是也有可能会导致无法中断线程(虽然这个可能性很小,但是只要一旦发生这种情况就会造成死循环了)。
下面解释一下这段代码为何有可能导致无法中断线程。在前面已经解释过,每个线程在运行过程中都有自己的工作内存,那么 线程1 在运行的时候,会将 stop 变量的值拷贝一份放在自己的工作内存当中。
那么当 线程2 更改了 stop 变量的值之后,但是还没来得及写入主存当中, 线程2 转去做其他事情了,那么 线程1 由于不知道 线程2 对 stop 变量的更改,因此还会一直循环下去。但是用 volatile 修饰之后就变得不一样了:
- 使用 volatile 关键字会强制将修改的值立即写入主存;
- 使用 volatile 关键字的话,当 线程2 进行修改时,会导致 线程1 的工作内存中缓存变量 stop 的缓存行无效(反映到硬件层的话,就是CPU的L1或者L2缓存中对应的缓存行无效);
- 由于 线程1 的工作内存中缓存变量 stop 的缓存行无效,所以 线程1 再次读取变量 stop 的值时会去主存读取。
- 那么在 线程2 修改 stop 值时(当然这里包括2个操作,修改线程2工作内存中的值,然后将修改后的值写入内存),会使得 线程1 的工作内存中缓存变量 stop 的缓存行无效,然后 线程1 读取时,发现自己的缓存行无效,它会等待缓存行对应的主存地址被更新之后,然后去对应的主存读取最新的值。那么线程1读取到的就是最新的正确的值。
指令重排序
指令重排序,一般来说,处理器为了提高程序运行效率,可能会对输入代码进行优化,它不保证程序中各个语句的执行先后顺序同代码中的顺序一致,但是它会保证程序最终执行结果和代码顺序执行的结果是一致的。
volatile 关键字禁止指令重排序有两层意思:
- 当程序执行到 volatile 变量的读操作或者写操作时,在其前面的操作的更改肯定全部已经进行,且结果已经对后面的操作可见,在其后面的操作肯定还没有进行;
- 在进行指令优化时,不能将在对 volatile 变量访问的语句放在其后面执行,也不能把 volatile 变量后面的语句放到其前面执行。
对于使用双重检查锁定实现单例的方式,单例的引用会声明为volatile,这里的volatile有什么作用?1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19public class Singleton {
private Singleton(){}
private volatile static Singleton instance;
public static Singleton getInstance() {
Singleton tempInstance=instance;
if (tempInstance == null) {
synchronized (Singleton.class) {
tempInstance=instance;
if (tempInstance == null) {
tempInstance = new Singleton();
instance = tempInstance;
}
}
}
return tempInstance;
}
}
instance = new Singleton();通过这一行代码创建一个对象,可以分解为如下的三行伪代码:1
2
3memory = allocate(); //1:分配对象的内存空间
ctorInstance(memory); //2:初始化对象
instance = memory; //3:设置instance指向刚分配的内存地址
上面三行伪代码中的2和3之间,可能会被重排序(在一些JIT编译器上,这种重排序是真实发生的)2和3之间重排序之后的执行时序如下:1
2
3
4memory = allocate(); //1:分配对象的内存空间
instance = memory; //3:设置instance指向刚分配的内存地址
//注意,此时对象还没有被初始化!
ctorInstance(memory); //2:初始化对象
如果发生重排序,另一个并发执行的线程B就有可能在第一次为空判断instance时不为null。线程B接下来将访问instance所引用的对象,但此时这个对象可能还没有被A线程初始化!
当声明对象的引用为volatile后,上面的三行伪代码中的2和3之间的重排序,在多线程环境中将会被禁止。
volatile 的原理和实现机制
前面讲述了源于volatile关键字的一些使用,下面我们来探讨一volatile到底如何保证可见性和禁止指令重排序的。下面这段话摘自《深入理解Java虚拟机》:
观察加入volatile关键字和没有加入volatile关键字时所生成的汇编代码发现,加入volatile关键字时,会多出一个lock前缀指令
lock前缀指令实际上相当于一个内存屏障(也成内存栅栏),内存屏障会提供3个功能:
- 它确保指令重排序时不会把其后面的指令排到内存屏障之前的位置,也不会把前面的指令排到内存屏障的后面;即在执行到内存屏障这句指令时,在它前面的操作已经全部完成;
- 它会强制将对缓存的修改操作立即写入主存;
- 如果是写操作,它会导致其他CPU中对应的缓存行无效。
参考
- 《Java并发编程的艺术》
- https://legacy.gitbook.com/book/chenkaicheng/java-android/details
- https://yuweiguocn.github.io/java-instance/
