
本文对混淆输出的文件及作用进行了介绍。
《古郎月行》
小时不识月,呼作白玉盘。
又疑瑶台镜,飞在碧云端。
—唐,李白
原文链接:Reading ProGuard’s Outputs
混淆的输出
当混淆处理一个android应用,它生成的几个输出文件说明了每一步发生了什么。这些文件对于理解混淆做了哪些修改很有帮助。这些文件并不是自描述的文档,因此我来带你看下这些文件为什么被创建和说明了什么。
这些文件在构建目录下,就像这样:
1 | app/build/outputs/mapping/{buildType}/ |
这有一个图说明了混淆在分析一个应用时所处理的步骤,这些步骤输出的文件很整齐。这些步骤参考了一些上下文环境。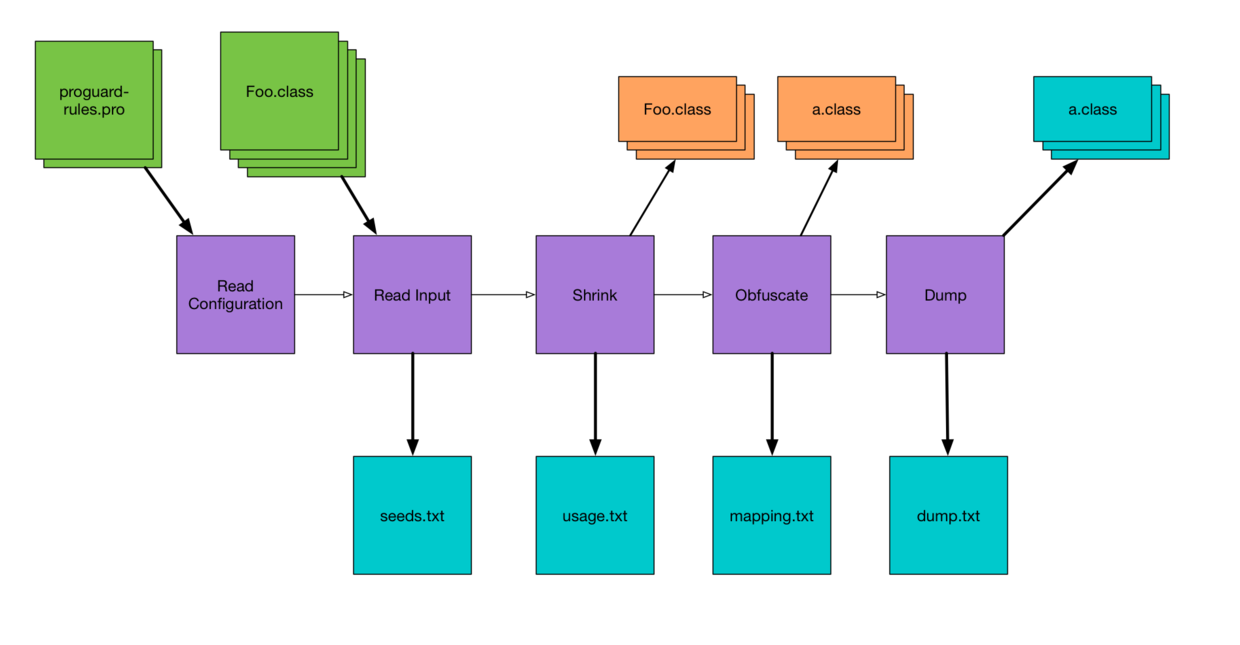
seeds.txt
混淆的第一件事情就是读取配置的所有文件,然后读取所有的java字节码(.class文件)创建class池。混淆然后查看class池并且将匹配所有keep规则的每个类和成员的列表输出到seeds.txt。这对于调试你写的keep规则是否匹配到了尝试keep的类很有帮助。

如果一个类被匹配,会有一行全类名。对于一个成员是全类名后是成员签名。
usage.txt
知道了哪些代码是keep的,混淆将继续在class池查看不需要keep的代码。这是代码压缩阶段,混淆会从应用中移除未使用的代码。正如它所做的这个,它会输出未使用的代码——将会被移除的代码到usage.txt。这对我来说有点不解;我认为它应该叫ununed.txt 或 shrinkage.txt 或者其它什么的。
这对于理解为什么一个类在运行时不存在很有帮助。你可以检查它是否被移除到了这里,或在下一步中被重命名了。

如果整个类被移除,会有一行全类名。如果只有类中某些成员被移除,会在下一行输出被移除的成员。
mapping.txt
混淆下一步需要做的是混淆尽可能多的代码,它会重命名类和成员为无意义的名称如“a”,“b”等等。混淆会输出每个类和成员的原名和新名到 mapping.txt。并不是所有的代码被重命名,但所有的代码会被列在mapping.txt。
如果你在尝试反混淆那你需要这个文件。它可以让你从被混淆的名字映射到原始代码的名字。
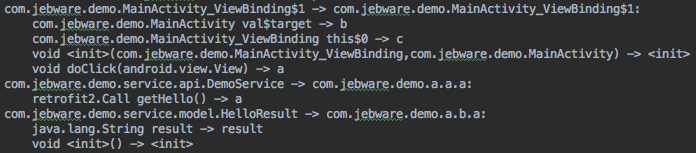
每行的格式是“{原名字} -> {新名字}”。在类名称下面的是类的每个成员。注意构造方法显示为“
dump.txt
然后混淆就完成了它所有的工作(压缩代码和混淆),它输出了最后一个很重要的文件——所有代码被处理后的完整列表。就是所有的class文件,格式并不是最优的,所以它是个巨大的文件。我有一个测试混淆的示例应用,最终应用大小约1MB,但dump.txt接近18MB。下面是某一个类的输出: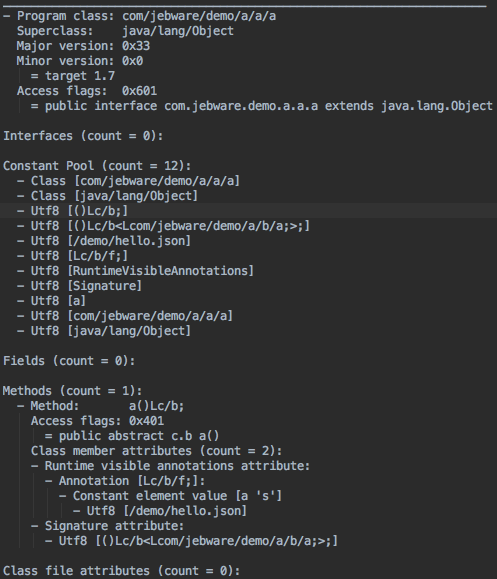
如果你想看看类文件是什么但不想反编译.class或.dex文件,这将会很有帮助。
存档
最后一点需要注意的是这些文件是构建的重要的一部分,尤其是mapping.txt。如果这个构建将要分发到应用市场,你需要使用mapping.txt反混淆堆栈信息。
